
pandas로 데이터핸들링하는 과정에서 groupby()한 output을 Dataframe형태로 사용하기 위해 공부한 내용이다.
df.groupby(['뭐로','그룹지을지']).reset_index() 이런느낌으로 사용하면 된다.
예제
1
2
3
import pandas as pd
df = pd.read_csv("example.csv",encoding='cp949')
df.info()
1
2
3
4
5
6
7
8
9
10
11
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000000 entries, 0 to 999999
Data columns (total 26 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 IDV_ID 1000000 non-null int64
1 SEX 1000000 non-null int64
2 AGE_GROUP 1000000 non-null int64
...
dtypes: float64(19), int64(6), object(1)
memory usage: 198.4+ MB
26개의 column을 가진 df를 로드했다.
이 df를 성별과 연령별로 사람 수를 보려한다면, 그 중에서도 성별이 1(남자)만 보겠다~면~
1
2
dff = df.groupby(['SEX','AGE_GROUP'])
dff.IDV_ID.size().reset_index()[dff.IDV_ID.size().reset_index().SEX==1]
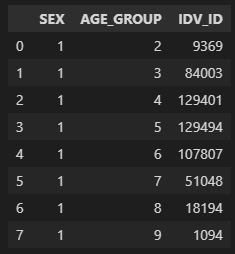
이런 느낌으로 사용하면된다~
참고
- Stackoverflow 게시글 Converting a Pandas GroupBy output from Series to DataFrame